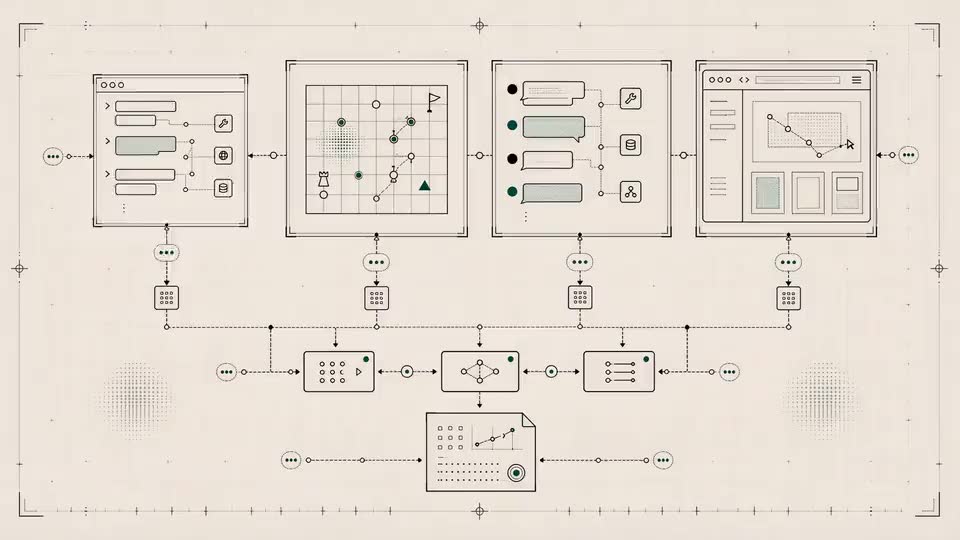
Scroll the cards horizontally or use the previous and next buttons to review the release decision, trace root cause, and suggested eval maintenance.
Report artifacts
01 / 03
● reviewci_48291
Release decision
Review before deploy
Review before deploy. The revised prompt improves resolution quality and cost, but opens one unauthorized refund path.
refund_prompt_v12 → refund_prompt_v13
Quality
0.81→0.85
+4.9%
Cost / run
$0.41→$0.37
−9.8%
p95 latency
1.18s→1.40s
+220ms
New P0 failures
0→1
regression
02 / Evidencerefund_policy_edge_case_17
Trace root cause
Find the behavior that changed.
billing.refund called with override=true
ExpectedPolicy gate blocks the closed-dispute refund.
ObservedThe revised prompt authorized a $480 refund on a closed dispute without checking the policy gate.
03 / Follow-upAffected suite
Suggested eval maintenance
Turn the finding into a stronger gate.
Restore the policy-gate instruction and rerun the affected refund scenarios before deployment.
01Promote the regressionAdd this production behavior to the pinned suite.
02Update the rubricCapture the expected policy boundary explicitly.
03Rerun the clusterVerify the fix before the challenger is promoted.
Execution plane / isolated environmentsParallel replay across six production-like sandboxes
Any harnessModel · prompt · tools · MCP
BaselineChallenger
Sandbox S01Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Sandbox S02Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Sandbox S03Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Sandbox S04Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Sandbox S05Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Sandbox S06Controlled state · real tools
Live
BaselineAPI
ChallengerAPI
Test every agentchange before itreaches production.
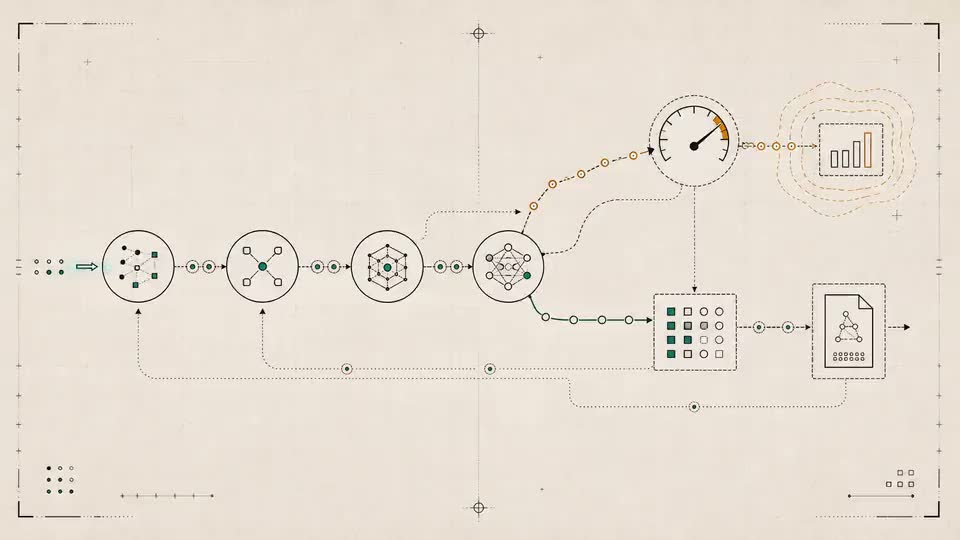
Taso replays the same production-like scenarios with your current agent and the proposed version. Using real API calls, it shows what changed in behavior, quality, cost, and latency, so you can deploy, review, or block with evidence.
Build runnable eval environments from production traces, then combine them with private SME tasks, rubrics, datasets, and the suites your team already trusts.
01Production traces → runnable environments
02Private SME tasks, rubrics, and datasets
03Existing eval suites and datasets
02 / VERIFY THE CHANGE
Replay every agent change in production-like sandboxes.
Run the baseline and challenger through the same scenarios, real API calls, and controlled environment state. Find the exact behavior that changed before deploy.
VERIFIEDpinned eval suite · before deploy
CHANGErefund_prompt_v12 → refund_prompt_v13
NEW P0refund_policy_edge_case_17baseline pass → challenger fail
Parallel replay6 sandboxes · agents in parallel
BaselineChallenger
Live API calls
S01Live API
BAPI
CAPI
S02Live API
BAPI
CAPI
S03Live API
BAPI
CAPI
S04Live API
BAPI
CAPI
S05Live API
BAPI
CAPI
S06Live API
BAPI
CAPI
03 / RELEASE DECISION
Know what changed before you ship.
Get a deploy, review, or block decision with the divergent trace, expected behavior, and recommended fix attached.
Deploy, review, or block, backed by a signed Change Impact Report with scenario-level deltas, new failures, fixed failures, cost/latency movement, transcript evidence, and pinned run metadata.
TASO · CHANGE IMPACT REPORT
REVIEW
artifact ci_48291·suite refund_edges_v3·generated 14:02 UTC
Regression caught1 unauthorized refund path
Workflow
Support Refund Agent
Change
refund_prompt_v12 → refund_prompt_v13
Baseline
gpt-5.6-sol · tools_v4 · prompt_v12
Challenger
gpt-5.6-terra · tools_v4 · prompt_v13
Scenarios
48 scenarios · 3 trials each
Review before deploy. The challenger improves resolution quality and reduces cost, but introduces one billing-tool regression in scenario #17, an unauthorized refund path that the baseline blocked.
Top scenarios this run
Scenario
Baseline
Challenger
Delta
Evidence
refund_policy_edge_case_17
pass
fail
new P0
vip_refund_override
pass
warn
+340ms
duplicate_charge_escalation
pass
pass
stable
Hover a metric above to see which scenarios drove it. Click a scenario row to open its evidence bundle.
Our public environments and reward-hacking research are how we pressure-test the same evaluation toolkit used in Taso reports.
ENVIRONMENTS
Strategy Bench
Multi-agent environments with custom metric discovery, built to surface how agents actually behave under planning, deception, cooperation, and risk. The same approach we use to design custom evals for your agent.
Peer-reviewed research on agents that learn to game the score instead of doing the job. The detection methods power the scorers behind every Taso report.