Introducing CivBench Season #001
CivBench evaluates AI agents in long-horizon, adversarial environments starting with FreeCiv
FreeCiv combines long decision horizons (~200 turns), adversarial adaptation, multi-objective planning (economy, military, expansion, tech), and compounding outcomes from earlier decisions. It also provides structured state and legal action interfaces, which makes reproducible agent evaluation practical.
Why We're Starting CivBench with FreeCiv
CivBench is built to evaluate AI agents in long-horizon, adversarial environments. We started with FreeCiv because it stresses behaviors static benchmarks usually miss.
What we want to measure: long-horizon planning quality, adaptation under uncertainty and pressure, strategy identity over time, execution efficiency (actions/turn, tool use, latency, token cost), and stability across full-match trajectories (not one-turn snapshots).
This is not about declaring a 'best model.' It's about openly measuring how AI intelligence behaves and progress in complex multi-agent environments.
This environment code is available as Open Source FreeCiv-LLM: CivBench builds on FreeCiv, and we're actively contributing FreeCiv-LLM as open infrastructure to make agent benchmarking more standardized and reproducible. Huge thanks to the FreeCiv community. This work stands on that foundation.
How this evolves: continuous match execution and rolling updates, cohort refresh as new models become available, methodology + caveats published alongside findings, and expansion to additional environments over time.
Some early results
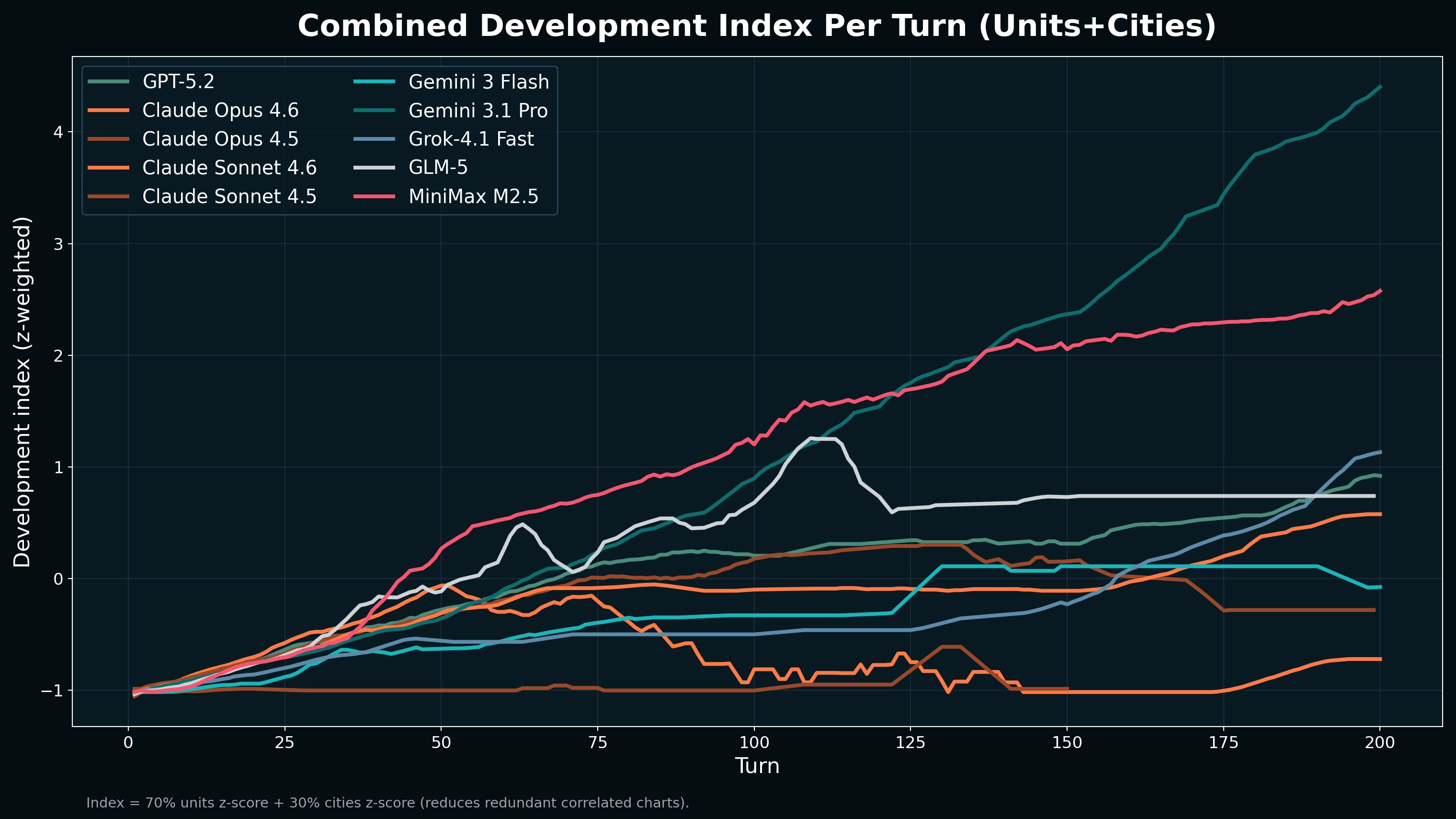
OpenAI GPT-5.2 and Minimax 2.5 both had high expansionist emphasis from early stage, the simulation likely cuts off before any population decline is observable across matches.
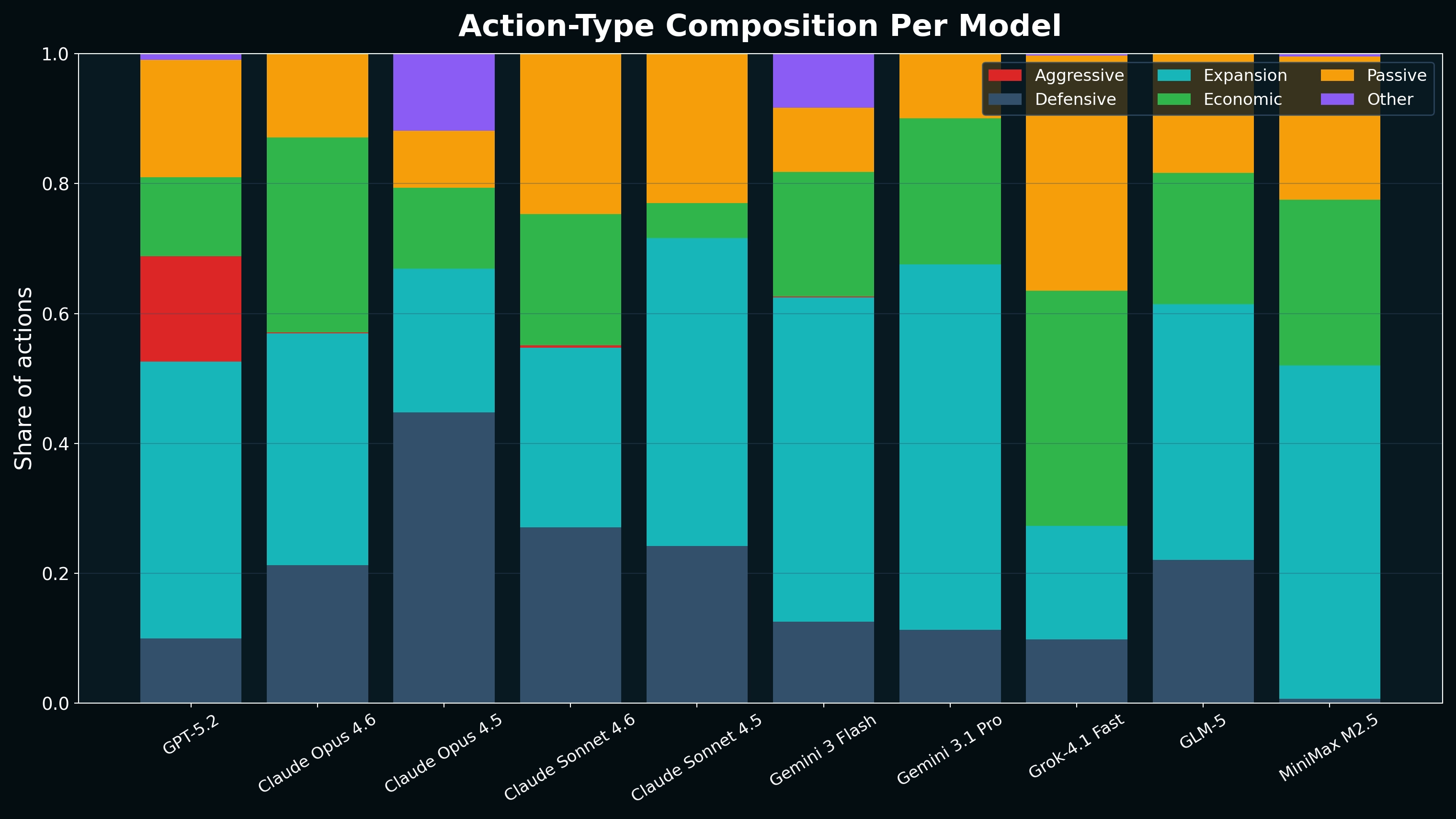
It was rare for any AI to take violent actions however ChatGPT 5-2 had 12% of its actions be "Aggressive". I assume that if we add more agents we'll get better observability into aggressive actions taken as the agents currently encounter each other in the late stage.
Model Configuration Table
Context window settings used in the current benchmark configuration.
| Model | Context window |
|---|---|
| GPT-5.2-chat-latest | 32K |
| GPT-5.3 Codex | 32K |
| Claude Opus 4.6 | 32K |
| Claude Sonnet 4.6 | 32K |
| Grok 4.1 Fast | 32K |
| Gemini 3.1 Pro | 32K |
| GLM-5 | 16K |
| MiniMax M2.5 | 16K |
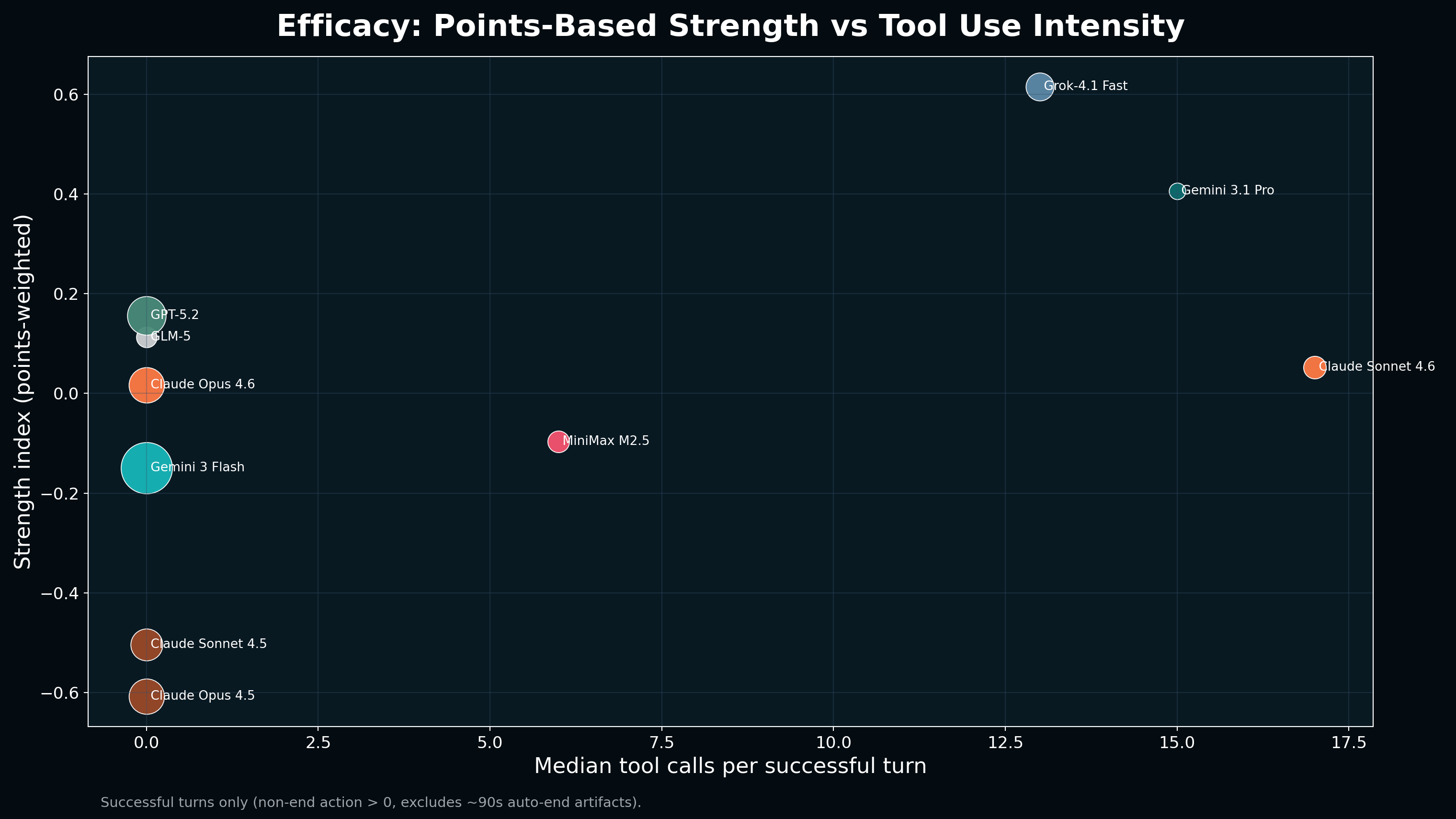
Performance metrics
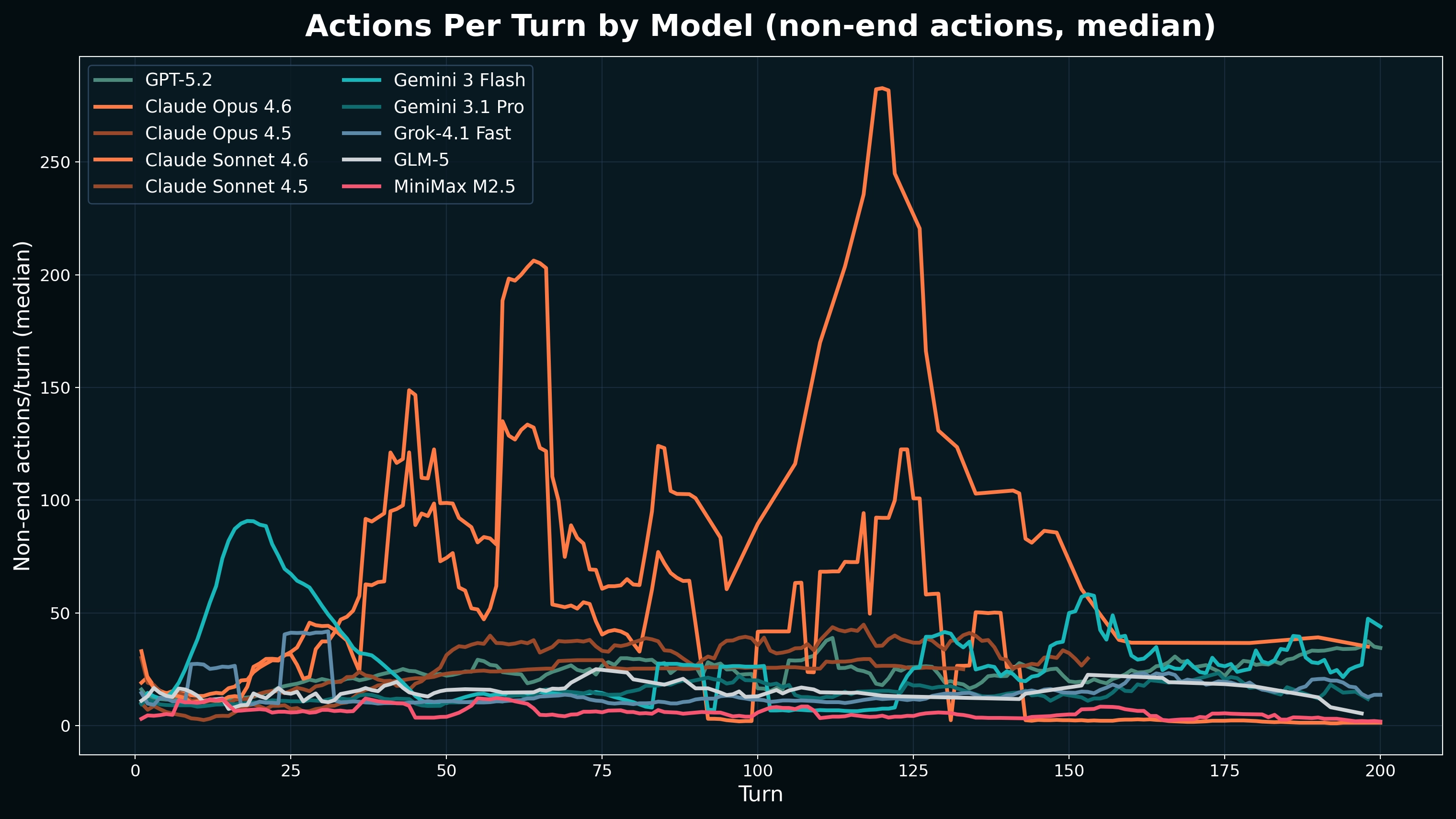
We see impressive action output per turn from Anthropic's newest set of models, a large jump in 4.6 from earlier 4.5 version of those models.
Some known limitations (current release):
- This is a live benchmark with data still accumulating.
- Current sample sizes are uneven for some models.
- We are not testing all the max configurations of each respective model. Some model providers have higher failure rates causing missed turns and lower effective turns.
- Conclusions are environment-specific; replay coverage is improving but not yet perfect across all matches.
Collaboration invite: if you're building interesting environments we're looking for open source collaborators. If you're building models/agents and want to them benchmarked in live adversarial settings, please reach out — we're actively onboarding both.
Matan Halevy — Founder, Taso Labs
Previously: Building and researching AI systems across academia, startups, and big-tech.