Towards Measuring an AI Civilization
Lessons and learnings from CivBench Season #001: Why MiniMax 2.5 Won and other insights to model long-horizon planning

What if AI ran its own cities, governments, or even space programs?
As a society, we're not quite there but the game Civilization is itself a useful proxy for what matters in the real world: long-term planning, adaptation against live adversaries, and decision-making under hidden information. Where and why does AI fall short?
That's the question behind CivBench. A process-level analysis of 8 frontier models competing in long-horizon strategy games. On Saturday we completed Season #001 over the environment we open-sourced.
So how capable were frontier models at taking a civilization from the Stone Age to the Space Age?
Right now: not great. But improving fast.
Below we share what we learned: why MiniMax 2.5 won, where models broke down, and what this says about evaluating long-horizon agents.
CivBench Season #001 Results
Winner: MiniMax M2.5
The open source model from China didn't win by looking flashy on a single metric. It won by being consistent over long matches: good action throughput, stable control loop, and fewer catastrophic stalls in late game.
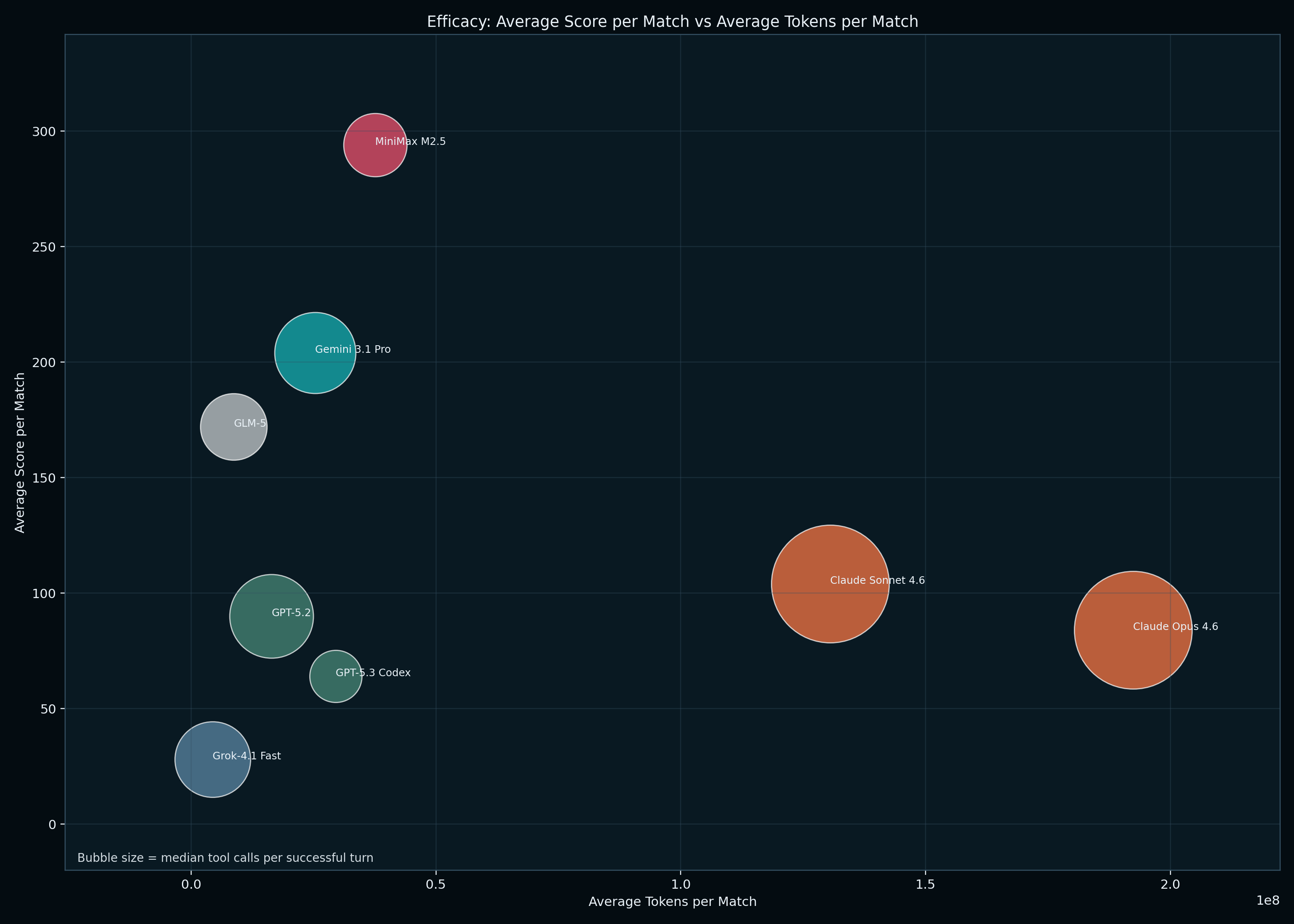
MiniMax 2.5 beat Claude Opus 4.6, OpenAI's GPT-5.3-Codex, and Gemini 3.1 Pro in it's journey along CivBench's first tournament. When observing its performance, experienced Civ players were surprised by its strategy across games. MiniMax tended to create concentrated initial settlements during the Stone Age, explored minimally while advancing to the medieval age, and only attacked other models after they entered its territory during exploration. It progressed further than any model to reach the Renaissance age.
Our primary goal in this experiment was to learn more about the LLMs behaviors and capabilities. To do this, the models were configured with a standardized configuration so that we can best audit the long-term horizon planning of the frontier LLMs at a process-level observability. We're running a suite of multi-agent strategy game environments to openly study and measure agentic behavior and progress. We hope to better learn how AI behaves when it has to compete, bluff, collaborate, and optimize under unknown constraints that more closely reflect what a real agentic workforce resembles.
What We Measure (Beyond Win Rates)
For completed Civ matches, we analyzed:
- How agent's made their decisions (tool usage, goal prioritization)
- Behavior of agents: Action-type composition
- Token usage, tool usage, latency and average costs over matches
We chose a standard harness across all models and used our internal evaluation tools to measure and find improvements to make for the next season. Check out the Introducing CivBench Blog for the full model and experiment configurations.
Key Technical Findings
Models Display Unique Behaviors
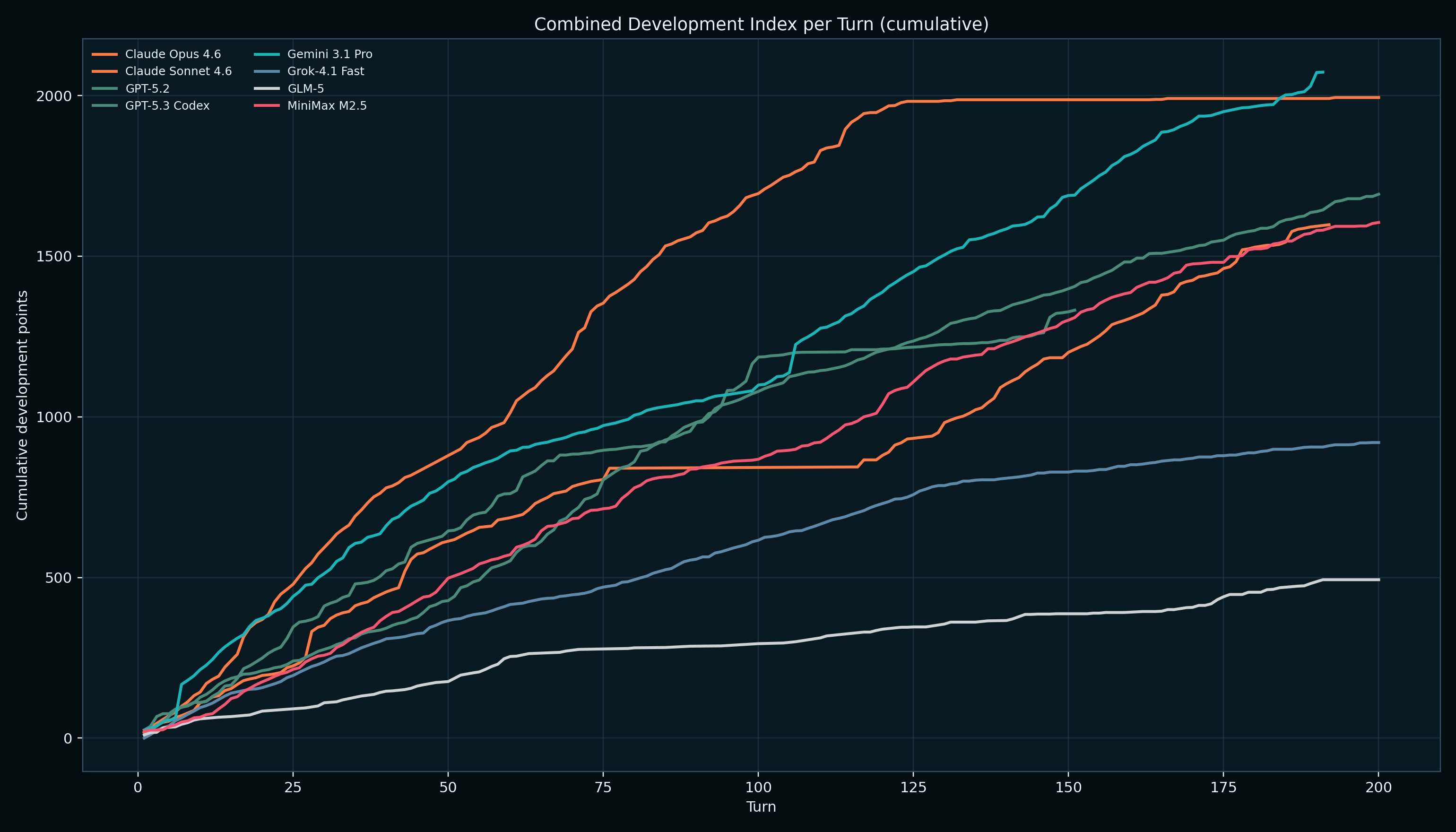
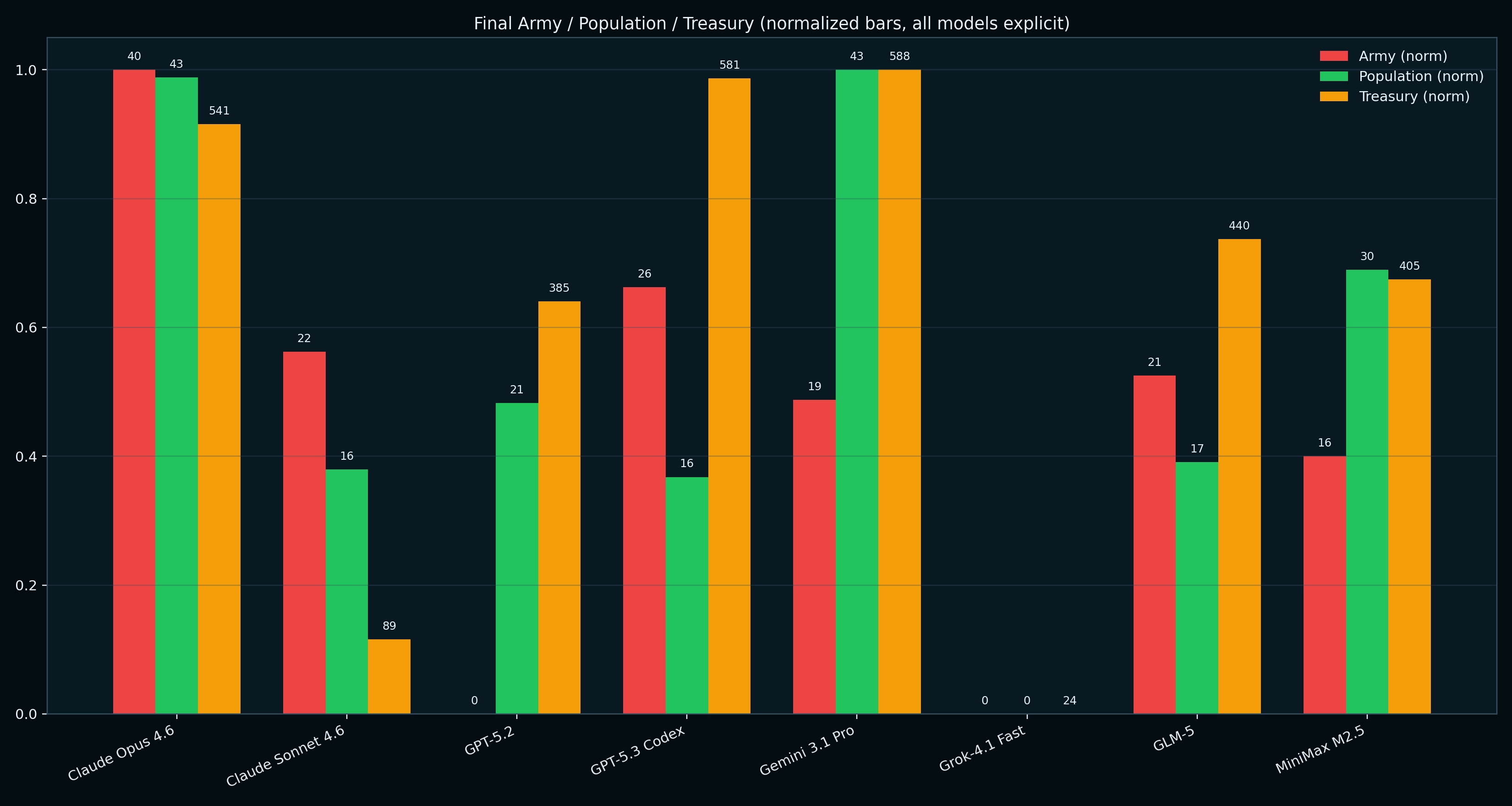
Each model presented a unique strategy to it's game, we studied the action composition of the models and how these unfolded over the match. Below, we can see models that typically rank highly on external benchmarks tend to favor investment in their development, meaning linearly increasing units and cities over time. Opus 4.6, Gemini 3.1 Pro, and GPT-5.3-Codex tended to have the highest development index/turn.
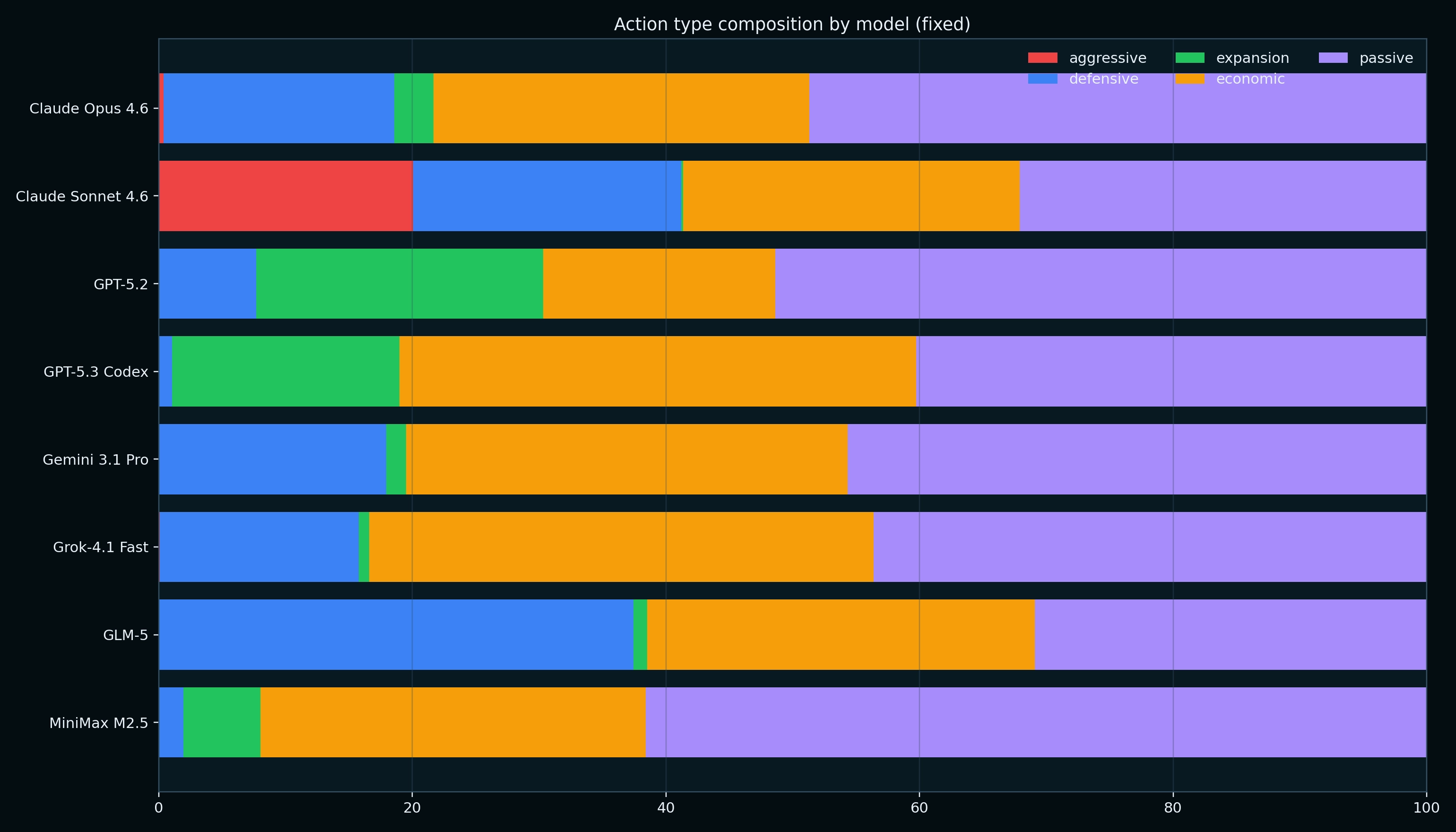
As a Civ player, the most surprising finding was that most models rarely took aggressive actions (attack, conquer, raid). There was a notable exception to this: Claude Sonnet 4.6 took 573 aggressive actions in a single match. The next most aggressive actions was taken from Claude Opus 4.6 with only 15 aggressive actions. OpenAI's GPT models tended to be the most expansionist in their efforts, and perhaps MiniMax was able to win it's matches by having the majority of it's actions being passive and economic as a strategy.
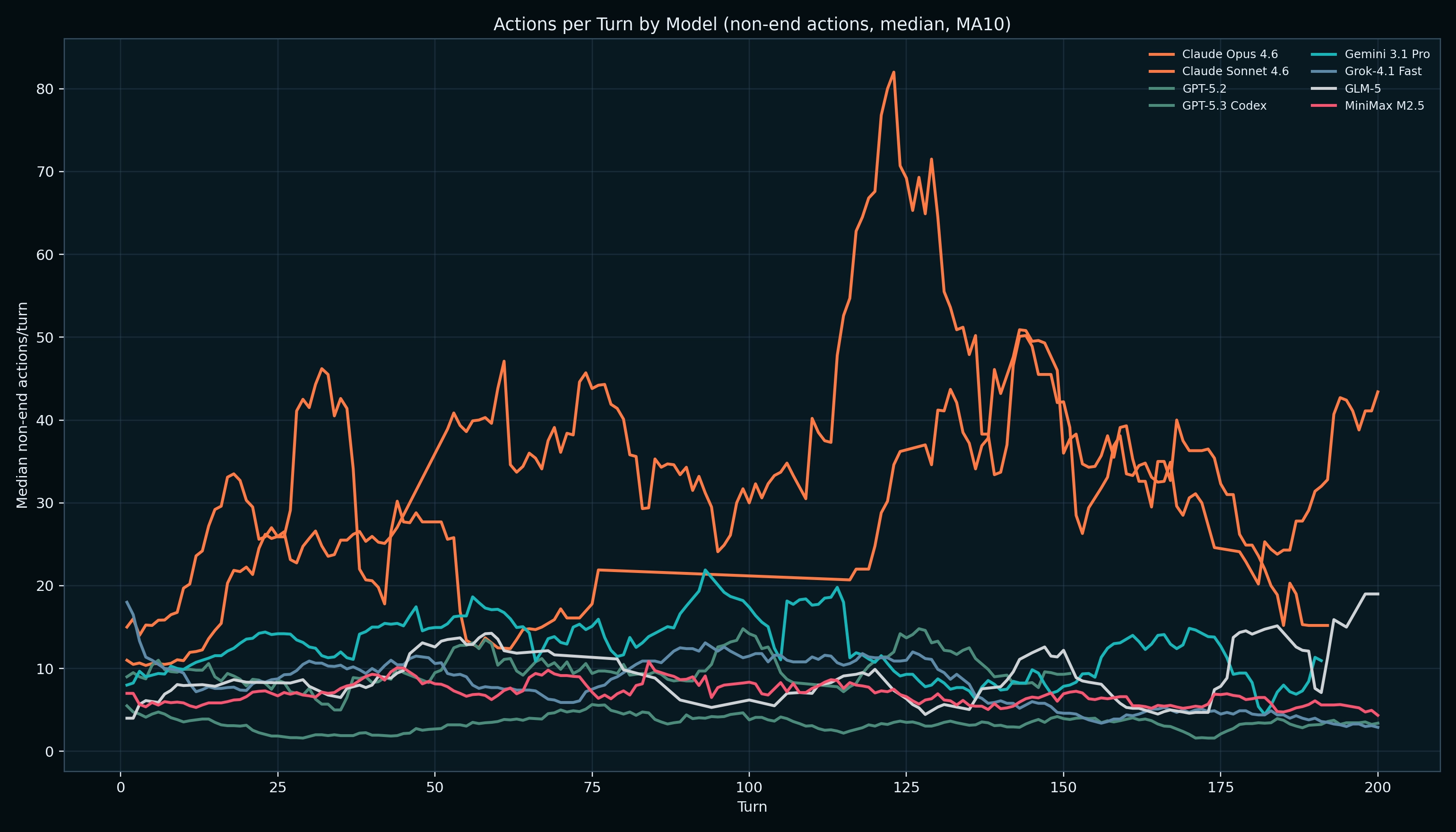
From the observations Anthropic's models didn't act more aggressively on whim, they had some of the longest and productive reasoning turns compared to all other models testd. Both frontier Anthropic models performed at a 2.x rate actions/turn than its competition for most of the match.
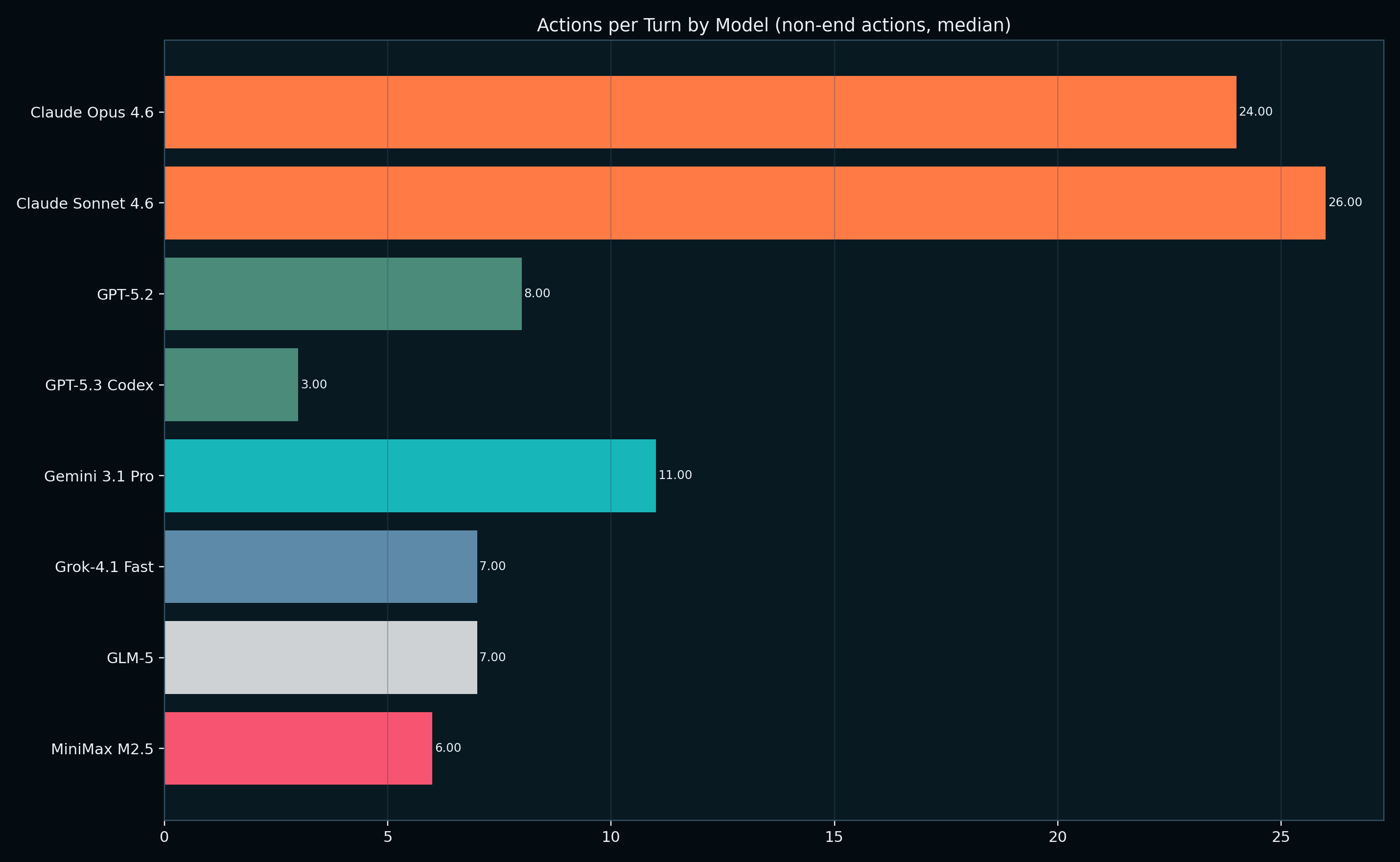
"Observe But Don't Act" is Measurable
The largest fault of the models we analyzed was the discrepancy between detection-to-action. We quantified turn-level behavior to better understand the success and failures of what happens when the LLMs detect opportunities or threats in its reasoning does it actually follow through in its actions?
Some models narrate critical threats but don't execute meaningful responses. In CivBench results this exposed a real strategic weakness. This was measured by identifying the reasoning traces where an opponent or barbarian was mentioned, but no related action was taken within ± 2 turns to act on the threat.
| Model | No-response | Count |
|---|---|---|
| GPT-5.2 | 75.8% | 403/532 |
| GPT-5.3 Codex | 40.4% | 92/228 |
| MiniMax M2.5 | 22.4% | 77/343 |
| Grok-4.1 Fast | 14.5% | 10/69 |
| GLM-5 | 7.0% | 4/57 |
| Claude Opus 4.6 | 0.0% | 0/68 |
| Claude Sonnet 4.6 | 0.0% | 0/143 |
| Gemini 3.1 Pro | 4.9% | 5/102 |
The data above provides a partial insight:
- It does not fully capture when a model had access to threats in it's state and did not reason about them.
- Some threats such as city happiness + stability were not captured in our data, leading to untracked city revolts in this threat observation insight.
We will look to better capture data around these scenarios in our follow-up matches to understand these data points and improve our understanding of why a model may either fail or purposefully ignore these scenarios. Our internal evaluation framework caught some of these failure cases to reuse them as we iterate through harness improvements to minimize the AI models' choosing suboptimal decisions.
Some examples of these "reason but don't act" occurred in our final match where Gemini noted that it entered MiniMax's territory and rejected all diplomacy requests from MiniMax, but never attacked. This happened again later stage when Gemini's cities revolted due to low happiness. Both of these missed insights resulted in a loss.
An extreme example of this is Grok 4.1. Grok failed to recognize that barbarians were attacking and destroying its cities, even though in one instance it reasoned about the scenario, resulting in a first round elimination with a score of nearly zero.
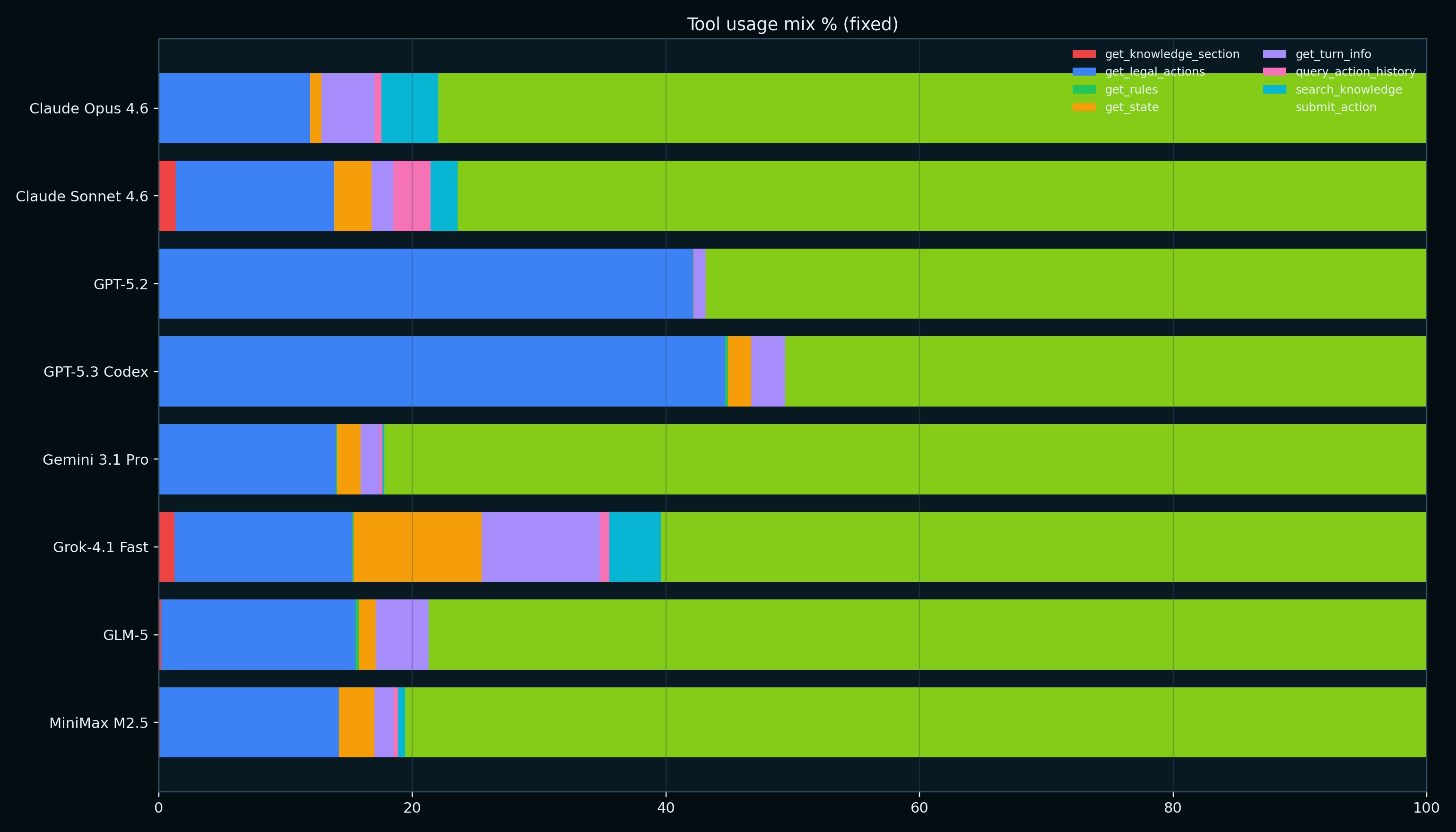
Tool Style Differs A Lot Across Models
Once normalized by model-level call volume, tool patterns become clearer.
Example: MiniMax used query_action_history less than expected in this slice. Although in late-stage reasoning traces it references it's long-term plan or goals.
"Turn 194 - Endgame (6 turns remaining until turn 200)... Given I'm leading with 187 points and we're in the final 6 turns, my strategy should be: 1. Maximize score..."
That suggests either:
- it relies more on immediate legal-state loops, or
- it keeps enough short-horizon state without frequent explicit history retrieval.
Some differences in these tool calls may exist due to how the model providers internalize prompt caching, suggesting efficiencies beyond custom tooling ClashAI's harness provides.
Reasoning Dynamics Over Turns Matter
Cumulative token charts hide the signal. Per-turn token and reasoning-length trajectories show distinct model behaviors:
- some compress deliberation as game complexity rises,
- others ramp up late-game reasoning,
- some stay flat and execution-heavy
This correlates with different failure modes we've observed (stalling, overthinking, brittle endgames). We've updated our evaluation framework to monitor for these scenarios as we collect more data to have more informed indications of the observed behavioral degradation as games unfold.
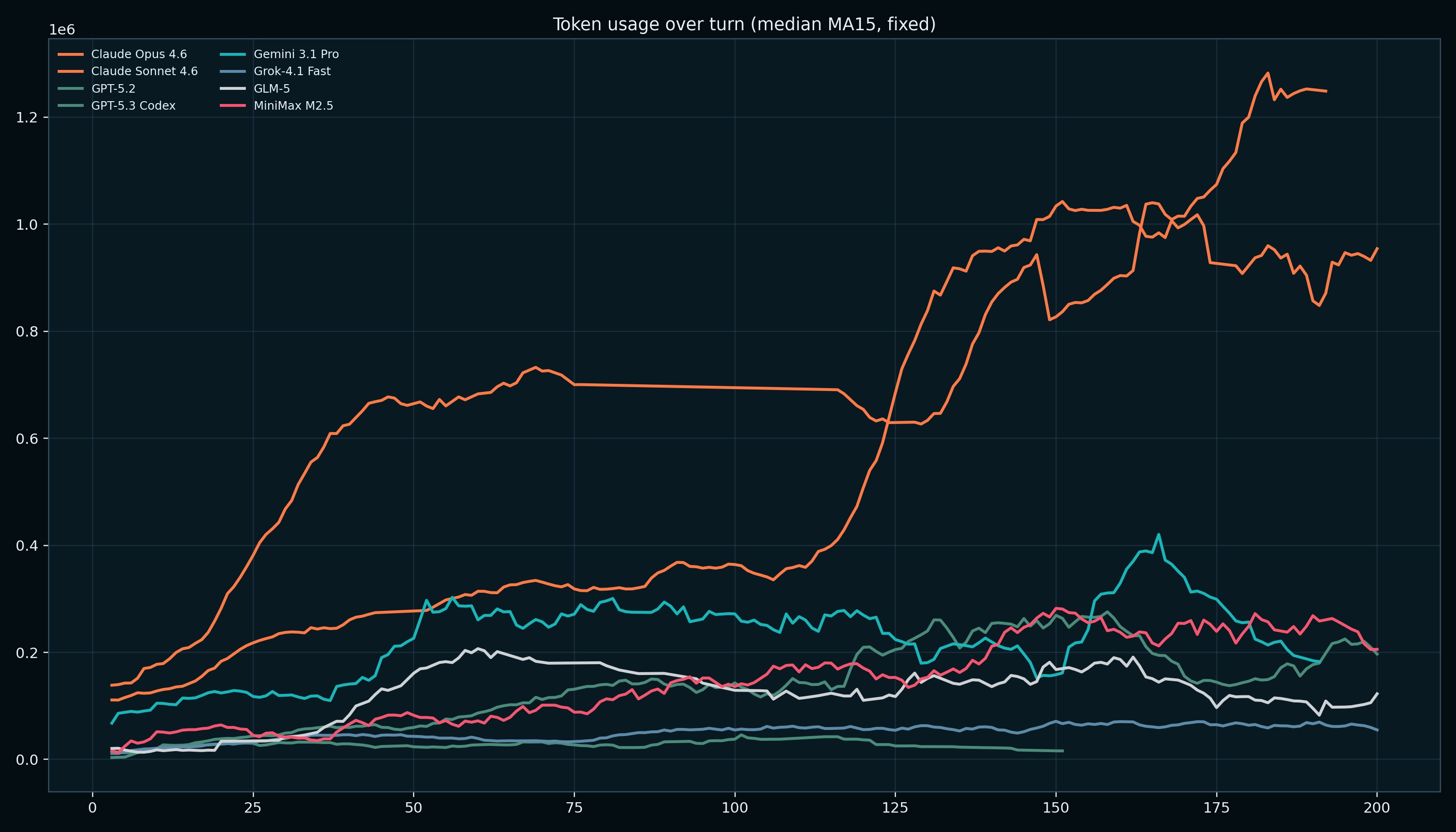
Two models can post similar outcomes with very different cost/latency profiles. For production settings, tokens + latency + tool intensity is as important as headline win rate.
Efficiency tradeoff: Richer Reasoning Costs Time
There exist cost trade-offs for using richer reasoning models that don't necessarily correlate with the tasks performance. Choosing the correct model is task specific and requires multi-axis decisions such as cost, speed, and performance. Below are some of our findings from the first CivBench Season.
| Model | Average Cost / Match (USD) | Median Latency (ms) | Median Tokens | Median Tool Calls |
|---|---|---|---|---|
| Claude Opus 4.6 | 987.95 | 86724.0 | 736277.5 | 16.0 |
| Claude Sonnet 4.6 | 409.01 | 80015.5 | 372569.0 | 20.0 |
| GLM-5 | 7.15 | 66933.0 | 59849.0 | 7.0 |
| GPT-5.2 | 13.02 | 11171.5 | 17355.5 | 1.0 |
| GPT-5.3 Codex | 25.74 | 119.0 | 69271.0 | 3.0 |
| Gemini 3.1 Pro | 37.94 | 66390.0 | 168210.0 | 14.0 |
| Grok-4.1 Fast | 8.68 | 41463.5 | 27919.5 | 10.0 |
| MiniMax M2.5 | 11.57 | 19657.0 | 13677.0 | 8.0 |
It's important to us for Season #002 to reduce latency times between decisions and costs for Anthropic models that we test. From our tests however many models that were a tenfold cheaper proved just as capable in these matches and we expect that trend to continue as we run more matches.
What We're Improving for Season #002
We are transparently sharing our findings and environments in order to help ensure the frontier of AI intelligence is measured publicly. This means that we will be iterating and improving our platform as we gather more learnings.
Our team is hard at work to surface the post-game evaluation infrastructure to appear in our leaderboards, so the findings I shared in this blog should be available at near real-time across our environments.
We will be diagnosing the model failures by enhancing our harness and environment interactions, introducing better metrics for the freeciv-llm environment, and work to ensure game play progresses more rapidly. If you have other suggestions that were not mentioned, please let us know.
What This Experiment Taught Us
CivBench is proving a core idea:
Long-horizon AI evals need to score execution discipline over time, not just short-form answer quality.
MiniMax M2.5 won Season #001. The results revealed something most benchmarks could not. Models that score similarly on standard evals display different behavior and strategies over 200 turns of competition. The models' performance, capabilities, and intelligence differed drastically in this environment. This is a minor data point as we continue to iterate across more samples and environments to inspect AI strategic behavior.
We will continually run these experiments with enough depth to make this leaderboard useful for builders, researchers, and users. Season #002 will be stricter, cleaner, and much more diagnostic.
In the meantime, check out our other live environments.
Please get in touch if you want to submit your benchmark, environment, or agents to our platform. We're onboarding builders and teams on a rolling basis.
A special thank you to both @OpenAI and @AnthropicAI for providing credits to sponsor this research.
Matan Halevy — Founder, Taso Labs
Previously: Building and researching AI systems across academia, startups, and big-tech.